Introduction
Here is a brief introduction to data science if anyone is interested. You can find many more resources to explore from here - there is a lot of support for this career path. You can probably find all of the resources you need online, if you’re dedicated and determined to learn. Don’t try to do it alone. Find a peer group. In person ideally, or online if you can’t find that.
I worked in the R&D department at State Farm around 2017. I was in a group of programmers and mathematicians, and we were mapping out the state of technology at the time and trying to understand and present how these technologies might be useful and interesting to State Farm. We got to explore blockchain in its early stages. Kubernetes - an operating system for a data center. And Deep Learning, which was becoming popular as a method for all kinds of predictive models. I spent my time reading white papers and building technology demos.
Foundations In Mathematics
Large Language Models or LLMs are the current vogue subject. LLMs are an extension of Deep Learning, or rather they are an application of Deep Learning towards the area of written human text. Deep Learning in turn, is a particular way of applying Neural Networks. And more generally, you could call all these approaches “Machine Learning”. So when most people say “AI” they really mean all these variations of Machine Learning, or ML.
In most areas of computer science, programmers run the show. But in the world of Machine Learning, it’s mathematicians who get hired to build these systems. Most people in the United States took algebra at one time or another, so let’s relate this back to a concept you already know. Do you remember graphing equations at one time or another?
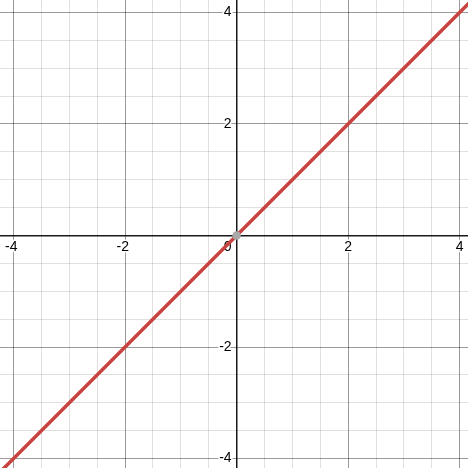
y = x
That’s a straight line, traveling at a 45 degree angle. Because every time X goes up by 1, y goes up by 1.
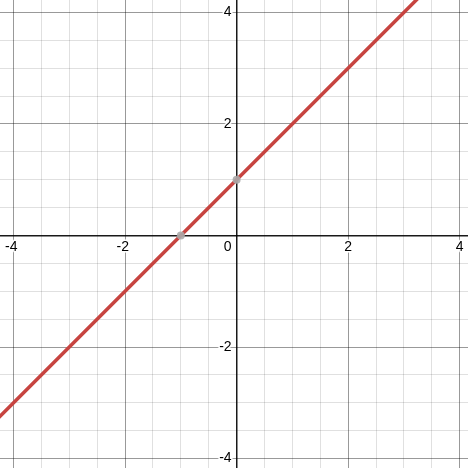
y = x + 1
Another straight line, except it’s 1 row higher.
And you know there are more complex algebraic equations, which create parabolas, sin waves, and other interesting shapes. With a graphing calculator, you can plug in different equations and see the resulting shape. Well, what if you have a shape, and you want to know what equation could produce it? We can use linear interpolation to do that. Human beings have been doing this for at least 2000 years (which is maybe a reality check for how smart we think we are).
Real Estate Example
This is interesting and “neat” but in order to be practical we usually want our mathematics to tell us something about the real world. So what about the real estate market? Intuitively you know that bigger houses are more expensive. Newer houses are more expensive. Houses in nicer zipcodes are usually more expensive - maybe because the weather is nice, or they have a nice view.
If you had a lot of market data (like maybe you’re Zillow) then you could use linear interpolation to get an approximate sense of how square footage affects the price of a house. But then you’ll find that this isn’t a very accurate predictor - you need to plug in the other data points that you know about. Linear regression is an approach you could use to integrate these different data points, and it does a pretty good job. If you take a data science class, often they will start by teaching you linear regression, because:
- Other methods while they may be more accurate are also more complicated to implement.
- Learning linear regression gives you a pretty good gut sense of what Machine Learning is about.
- Once you get the core concept, the other algorithms are just refinements on the concept.
As I mentioned earlier, neural networks (and all their variations and refinements) have pretty much taken over the space of predictive modeling. I think because 1) they’re flexible in terms of introducing new inputs, 2) they can produce pretty accurate results, given enough data.
Neural networks work by creating a network of weighted nodes that map the input to the output. Like square footage to home value, sticking to our example. You, the data scientist, perform a process called “learning” where you feed a whole bunch of historical data into it - you must know both the different data points of the home as well as the selling price. This trains the weighted paths within the network, and the resulting trained network is called a “model”. “Deep Learning” uses neural nets, but emphasizes backpropagation to perform corrections and increase the accuracy of the model.
The results of this can be pretty impressive: you apply the model and you get accurate predictions of home values. Most real estate agents will tell you however, that they don’t trust Zillow’s valuations. Part of that might be because they want to keep their jobs, but there’s also likely a lot of truth to it. Why is that? Because the map is not the territory. No matter how much data we plug into the model, we are limited by our own assumptions about what data is important and what isn’t. We may not even be capturing some of the data that is important. It may not even be possible to anticipate and capture all the important data.
Unsupervised Learning
The approaches we have talked about so far fall into the category of supervised learning where we know that our selected inputs are strong predictors of the output. But what if we don’t know which data is important, and we haven’t really begun to construct a theory of causation? In that case, we apply techniques of unsupervised learning to see if we can find causal links within the data. There are some pretty cool approaches in this category - Dynamic Quantum Clustering is one I have been really impressed by. I’m curious to see what new advancements emerge here. Dan, one of the mathematicians I worked with at State Farm, said that this approach was essentially applying Schrodinger’s Equation to the annealing process of the neural net. That alone is interesting - that an equation from quantum mechanics could be reapplied in such a different field with incredible results.
Unsupervised learning forms the core of the LLM models that are currently proliferating. Because the task of specifying all the causal links between human knowledge and human language would be impossible for anyone to do by hand, instead we rely on algorithms that can sense the pathways of causality within the data. Once these core pathways are determined, then “tuning” can occur, which is a supervised process where we have a known outcome we want (e.g. the model should be kind and helpful, whereas some of the human data it was trained upon may not be).
At this point you may also be interested in reading What implications do LLMs have for human society? This is more philosophical, and more for a general audience, but of course we are all impacted, whether we work on these systems or not. I also go into what these systems are capable of, and what they are likely not capable of unless we see a significant architecture change.
Other AI Models
Stuart Russel and Peter Norvig coauthored “Artificial Intelligence: A Modern Approach”. This continues to be a seminal work on AI, which is very helpful in understanding the landscape. Notably, in the above text I did not discuss:
- genetic algorithms
- goal oriented, agential systems
Genetic algorithms have a very interesting characteristic which is different from deep learning: they are self generating and evolving. An LLM needs massive resources and datasets to power its training. The economics of this drives us to do this process sparingly, get it right, and then get as much use out of the resulting model as possible before investing in training another. So an LLM doesn’t learn on the fly, whereas a genetic algorithm might be able to do so. There are also some interesting examples where genetic algorithms have discovered surprisingly elegant equations, whereas an LLM has a fixed number of parameters, and regardless of the pathways it constructs it will occupy the same space, and have the same compute complexity.
Agential systems are typically built as architectures around smaller building blocks. They can have the property of learning, adapting to their environment as they interact with it. They can be goal oriented. Check out TOGA meta theory if you want to go down a deep rabbit hole. ![]() You can see the beginnings of agential architecture being applied when ChatGPT or Grok say they have “updated their memory”. And more generally the entire environment that is set up around a chat model - you’re not just interacting with an LLM directly, you’re interacting with a state machine with an LLM embedded in it.
You can see the beginnings of agential architecture being applied when ChatGPT or Grok say they have “updated their memory”. And more generally the entire environment that is set up around a chat model - you’re not just interacting with an LLM directly, you’re interacting with a state machine with an LLM embedded in it.
Dynamic learning is the loop that’s largely missing with current LLMs - it’s computationally complex for them to truly integrate (backpropogate) their learnings on the fly into the underlying model, so we’re approximating that by updating what amounts to a hidden part of the conversation history. But comparing this to human cognition is like comparing a butter knife to a chainsaw. The learning process needs to get much more light weight, and much more effective, with less data to work from. Then you could apply that learning process on the fly, as the interaction with the environment is happening. We know that it’s possible, because the brains of living creatures do it. So there should be some architecture that we can build with similar capabilities. But in my view, whatever that is will be significantly different from deep learning. I’m not sure it can just be layered on, I think it will be a fundamental shift to another architecture. But who knows, I could be wrong.
From my State Farm colleagues I was also recommended the book Probabilistic Graphical Models (direct link to a large PDF). It’s pretty dense, and you’re going to need to understand the fundamentals before diving into this. But it’s something to aspire to. If you can grok it, then you’re playing at the cutting edge of the field.
One last thing I will mention - Deep Causality. If I understand the author correctly, this may be a more appropriate approach than LLMs when we want to process information on the fly - like lets say as a person types. A deep causality model can classify, tag, and act on the data in near real time, whereas an LLM is slow by comparison. You could use the two in tandem, for instance using Deep Causality to identify data to be processed further by an LLM.
Conclusion
This has been an overview of the landscape, which should give you some sense of whether you are interested in the field, and what specific areas of research may interest you most. It is quite amazing to take a step back and appreciate the achievements of our civilization, that we have discovered such deep and intricate truths such as mapping parts of the cognitive process… How much we have to learn, and what we can already accomplish with just the portion that we currently know.
Blessings and peace on your journey.